FIXED SCOPEone-off build
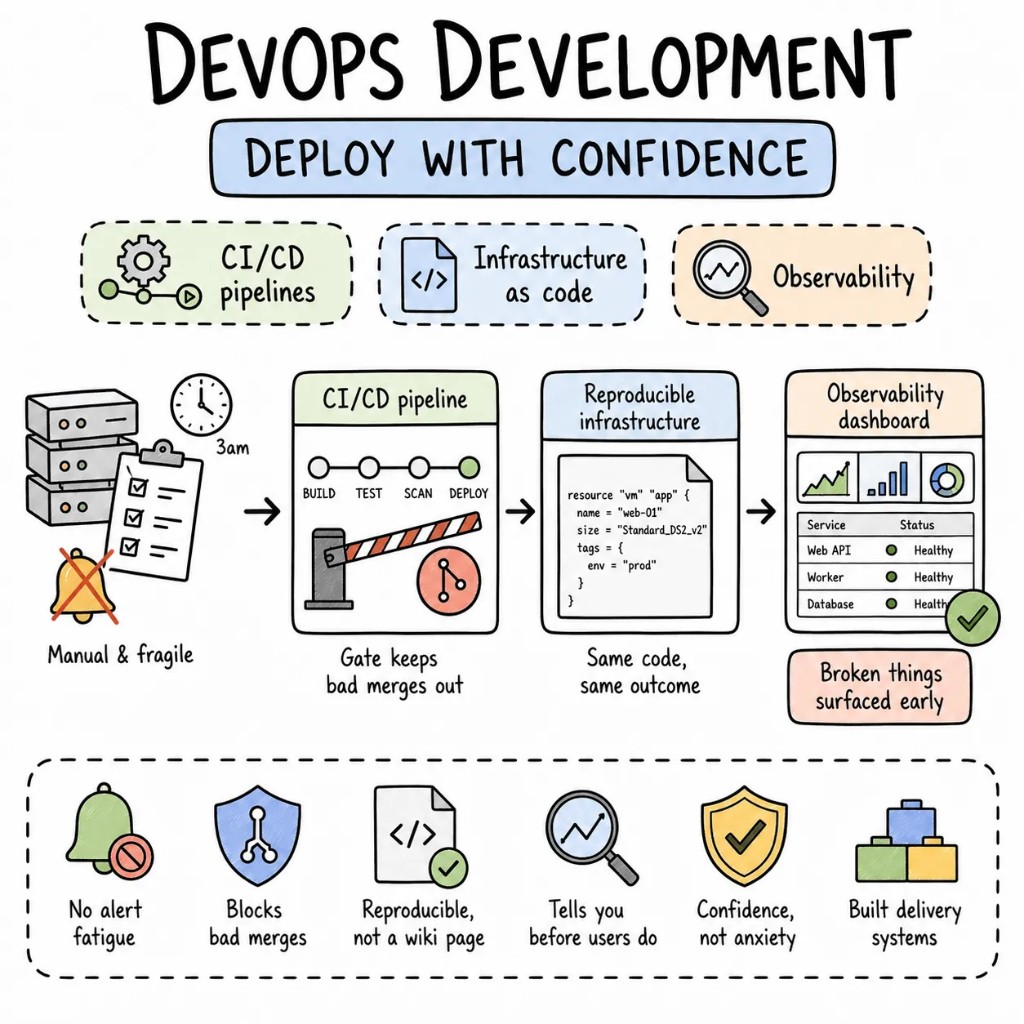
Ship a DevOps pipeline, end-to-end.
A defined scope, a fixed price, a senior-only team. From audit to production delivery system in 8–12 weeks.
$15k–$30k
FIXED SCOPE
- Zero juniors on client work
- Fixed quote in week 1
- Code, infra, runbook — yours